Asegúrese de actualizar su máquina Linux antes de profundizar en la implementación de este artículo. Para la actualización, use la utilidad «apt» de Linux con la palabra clave «update» y ejecute esta instrucción usando los privilegios «sudo». Aunque ahora podemos saltar a la implementación, preferiríamos actualizar este sistema también, es decir, una actualización disminuiría la posibilidad de que se produzcan errores y el sistema podría resolver los problemas con mayor precisión. Por lo tanto, use la utilidad «apt» dentro de las instrucciones de «actualización».
Veamos ahora la utilidad iconv de Linux en su consola de terminal. Por lo tanto, hemos estado ejecutando la instrucción «iconv» con el indicador «-l» para mostrar todos los conjuntos de caracteres codificados conocidos y más utilizados en la pantalla de nuestra terminal. Mostrará los conjuntos de caracteres codificados junto con sus alias. Puede ver una larga lista de conjuntos de caracteres codificados después de desplazarse un poco hacia abajo.
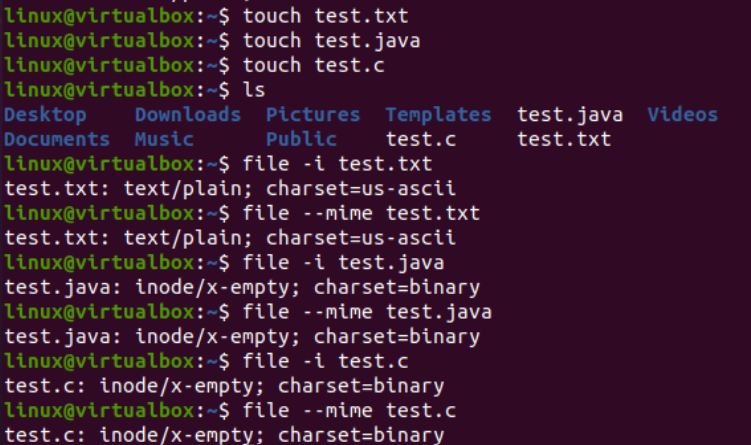
Ahora es el momento de comenzar con la implementación del comando iconv en Linux. Primero, necesitamos diferentes tipos de archivos en nuestro sistema para convertir un tipo de archivo a otro tipo. Por lo tanto, estamos utilizando la consulta «toque» en la terminal de la consola para crear tres archivos diferentes, es decir, tipo Java, tipo C y tipo de texto. Al enumerar los contenidos del directorio actual, encontrará los archivos recién generados en él.
Después de esto, veremos el tipo de cada archivo por separado usando la consulta «archivo» junto con el nombre de cada archivo. Esta consulta necesita la opción «-I» para mostrar el tipo de conjunto de caracteres de codificación para cada archivo por separado. Si olvidó usar la opción «-I», use la bandera «—mime» en su lugar. Los indicadores «-I» y «—mime» funcionan de la misma manera.
Ahora, después de ejecutar la instrucción «archivo» para el archivo de tipo «txt», obtuvimos la codificación de tipo de carácter «US-ASCII». Mientras usa la misma instrucción para los archivos Java y C, muestra que ambos archivos contienen codificación de tipo de carácter «BINARIO». Junto con eso, esta instrucción muestra que estos tres archivos están vacíos.
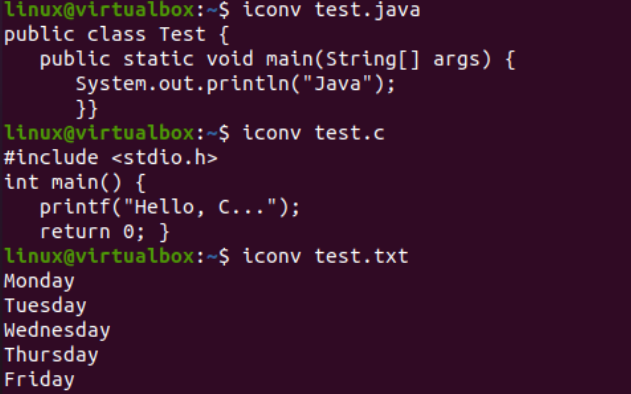
Ahora, ilustraremos el uso de la instrucción iconv en la consola para convertir un archivo de codificación de conjunto de caracteres específico a otra codificación de conjunto de caracteres. Antes de eso, debemos agregar algún código o datos a nuestros archivos. Por lo tanto, hemos agregado el código Java dentro del archivo «text.java», el código C dentro del archivo «text.c» y hemos agregado datos de texto dentro del archivo «test.txt». La consulta cat se usó aquí para mostrar el contenido de los tres archivos, como se presenta a continuación:
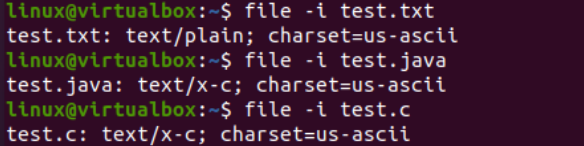
Ahora que hemos agregado los datos con éxito, veremos la codificación del conjunto de caracteres de estos archivos una vez más. Por lo tanto, hemos probado la misma instrucción de archivo dentro del shell con el indicador «-I» y los nombres de archivo, es decir, test.txt, test.java y test.c. Ejecutar estas tres instrucciones por separado para los tres archivos muestra que la codificación del conjunto de caracteres se ha actualizado para los archivos Java y C, mientras que permanece igual para el archivo de texto, es decir, US-ASCII. La codificación de archivos Java y C era anteriormente «binaria»; ahora, es «US-ASCII». Además, muestra que el archivo de texto contiene datos de texto sin formato, mientras que los otros dos archivos de código contienen los scripts como contenido.
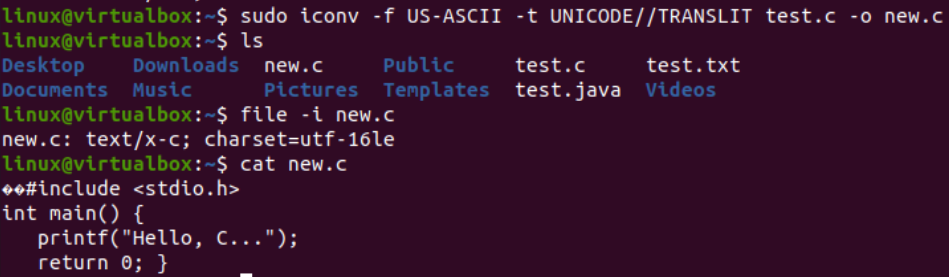
Es hora de realizar la tarea real necesaria para este artículo, es decir, convertir una codificación a otra usando el comando iconv en el shell. Por lo tanto, hemos estado usando la instrucción «iconv» dentro de la terminal de shell con los privilegios «sudo». Este comando toma la opción «-f» que significa «desde», y la opción «-t» significa «a», es decir, de una codificación a otra.
Después de la opción “-f”, debe especificar la codificación que ya tiene su archivo, es decir, US-ASCII. Mientras que después de la opción «-t», debe especificar la codificación que desea reemplazar con la codificación anterior, es decir, UNICODE. Debe especificar el nombre de un archivo utilizado como fuente con la opción –o para crear su imagen de objeto. La imagen del objeto sería otro archivo, es decir, “nuevo.c”, del mismo tipo pero con la nueva codificación y los mismos datos.
Después de ejecutar la siguiente instrucción, obtendrá un nuevo archivo en el mismo directorio, es decir, según la consulta «ls». Ahora, verificaremos la codificación del juego de caracteres de un nuevo archivo generado usando la instrucción iconv. Volveremos a utilizar la instrucción «archivo» con la opción «-I» y el nuevo nombre de archivo, es decir, nuevo.c.
Verá que el juego de caracteres para este nuevo archivo ha sido diferente del juego de caracteres de un archivo antiguo, es decir, el juego de caracteres UTF-16LE. Esto se debe a que hemos traducido la codificación US-ASCII a la codificación UNICODE usando la instrucción iconv para nuestro archivo new.c. La consulta «gato» mostró el mismo código C dentro del archivo pero comenzó con algunos caracteres Unicode, como ya se presentó.
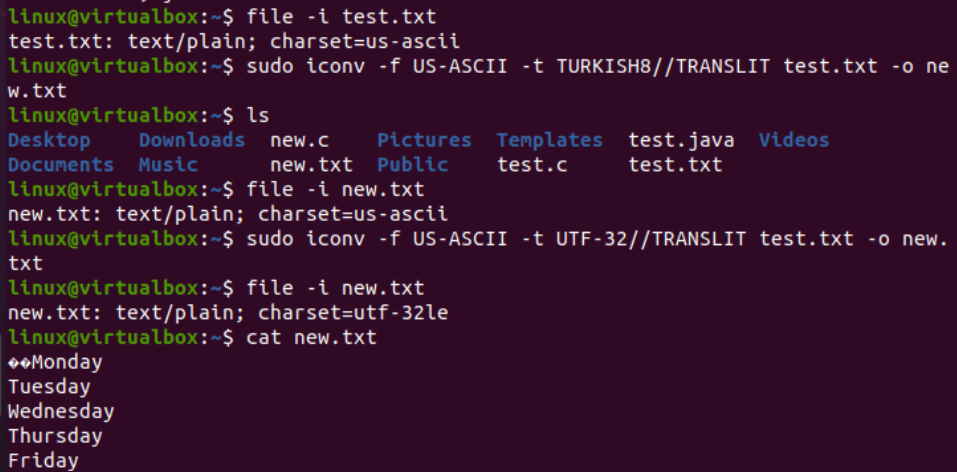
De manera muy similar, cambiaremos la codificación del archivo de texto test.txt. La instrucción del archivo muestra que tiene una codificación de conjunto de caracteres US-ASCII. El comando iconv se ha utilizado con el mismo formato para convertir la codificación del archivo test.txt de US-ASCII a TURKISH8. Verá que no cambia el US-ASCII a turco.
Después de esto, usamos el mismo comando para cubrir la codificación del juego de caracteres US-ASCII a UTF-32 para el mismo archivo. Esta vez, funciona. Esto se debe a que a veces puede haber un problema al convertir un conjunto de codificación a otro, o es posible que la otra codificación no lo admita.
Conclusión
Este artículo discutió cómo usar las instrucciones de iconv Linux para convertir un conjunto de caracteres de codificación a otro usando sus alias. De esta manera, tuvimos que crear algunos archivos de diferentes tipos.


 para transferir archivos")






